
Schema Evolution in Databricks Delta: What No One Tells You About Bronze, Silver, and Gold
Best Practices for Bronze, Silver, and Gold with SQL and PySpark

Schema Evolution in Databricks Delta: What No One Tells You About Bronze, Silver, and Gold
A practical guide for data engineers who want resilient medallion pipelines — without the silent disasters
Here’s a scenario I see constantly with engineers transitioning into modern data engineering:
A source system drops a column. Or adds one. Maybe renames it. The ingestion job either crashes immediately or — worse — silently swallows the change. Two weeks later, your Gold dashboards are showing wrong numbers, your data science team is asking questions you can’t answer, and you’re reverse-engineering what broke and when.
This is not a Databricks problem. It’s a schema governance problem. And Delta Lake gives you the tools to solve it — if you understand where the boundaries actually are.
Let me break this down layer by layer.
The Core Mental Model: One Rule to Anchor Everything
Here’s the practical rule that should govern your entire medallion architecture:
Let Bronze absorb additive changes safely. Make Silver and Gold evolve intentionally.
That’s it. Everything else flows from this.
Schema evolution in Delta Lake is a resilience feature for ingestion — not a substitute for data contracts and downstream engineering discipline. The moment you treat mergeSchema as a reason to stop thinking about what changes mean, you’ve taken on invisible debt that will surface at the worst time.
Why Source Schemas Change (And Why You Can’t Ignore It)
New columns get added. Old columns disappear. Names get changed in ways that look harmless but break your joins. Types shift from string to integer because the upstream team “cleaned up” their model.
Delta Lake addresses this with two fundamental features:
Schema enforcement — rejects writes that don’t conform to the existing table schema
Schema evolution — allows the schema to update when you explicitly opt in
This combination means you’re not stuck choosing between “fail on every upstream change” and “let anything through.” You get to be deliberate about it — by layer.
Medallion Layer Responsibilities
Think of each layer as having a different job, and therefore a different schema policy:
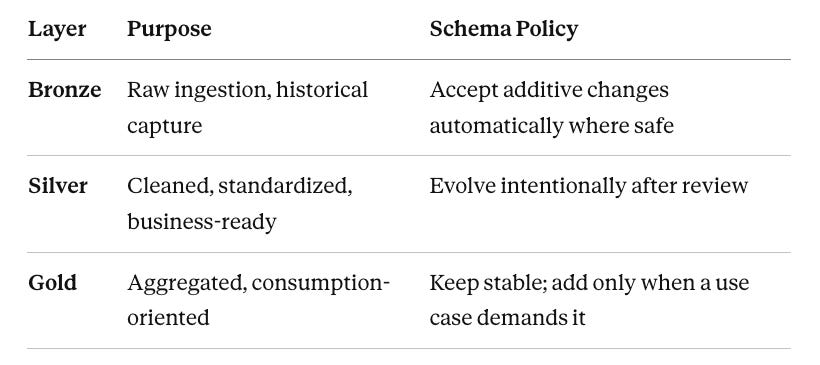
Bronze: Built to Absorb
Bronze should tolerate new columns automatically. This is where mergeSchema earns its keep.
PySpark — append with schema evolution:
bronze_df.write \
.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.saveAsTable("main.bronze.orders")
SQL — merge with schema evolution:
MERGE INTO main.bronze.orders AS t
USING staging_orders AS s
ON t.order_id = s.order_id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
WITH SCHEMA EVOLUTION;
Both patterns let a new source column land without dropping and recreating the target table. Table history is preserved. You don’t need an emergency deployment just because an upstream team added order_region to their API response.
That’s the Bronze promise: keep the historical record intact, don’t fail on harmless additions.
Silver: The Governed Transformation Contract
Silver is where the thinking happens.
Even though Delta can absorb anything upstream, Silver is where column naming, typing, nullability expectations, and business semantics get curated. A new Bronze column doesn’t automatically deserve a spot in Silver. Someone has to decide:
Does this column belong in the cleaned data model?
Does it need transformation before it’s usable?
Are downstream consumers ready for it?
PySpark — explicit column projection:
silver_df = (
spark.table("main.bronze.orders")
.select(
"order_id",
"customer_id",
"order_ts",
"status",
"new_source_column" # added deliberately after review
)
)
silver_df.write \
.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.saveAsTable("main.silver.orders")
SQL — explicit contract merge:
MERGE INTO main.silver.orders AS t
USING (
SELECT
order_id,
customer_id,
order_ts,
status,
new_source_column
FROM main.bronze.orders
) AS s
ON t.order_id = s.order_id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
WITH SCHEMA EVOLUTION;
Notice what both of these do: they name what’s going in. The contract is visible in the code. If someone reviews this PR, they can see that new_source_column was a deliberate choice, not an accident.
Gold: The Stable Product Layer
Gold should be the least surprising layer for anyone consuming your data.
New columns in Gold should only appear when there’s an actual reporting, analytics, ML, or product use case that requires them. If the new column matters for that use case — add it. If it doesn’t — leave Gold unchanged. Let Bronze and Silver hold it until there’s a reason to promote it.
This prevents source-system churn from leaking into dashboards and business-facing datasets. Your BI team should never open a report and find a column they didn’t know about.
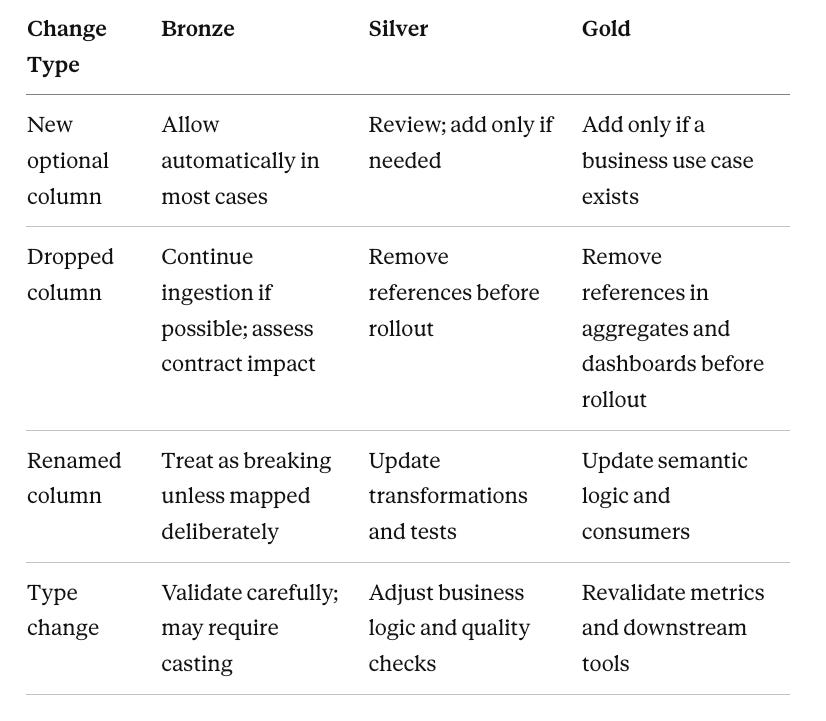
The More Dangerous Problem: Dropped Columns
Everyone asks about adding columns. The dropped column scenario is where teams actually get hurt.
Delta schema evolution helps you absorb additive drift. A removed column is a different situation.
If a source stops sending a column, Bronze doesn’t necessarily need to be rebuilt. New rows can still land with NULL in that position. Old rows retain their previous values. The table can keep running.
The real danger is downstream logic. If Silver or Gold notebooks contain:
SELECT dropped_col ...
WHERE dropped_col = 'X' ...
Those jobs will fail. The column is gone from the data but still referenced in the transformation code.
Safe response to a dropped column:
Confirm it’s truly deprecated at the source — not a temporary outage or deployment issue
Update Bronze ingestion expectations if the column was treated as mandatory
Remove or replace references in Silver transformations, tests, and expectations
Remove or replace references in Gold aggregates, dashboards, and semantic models
Optionally clean up the metadata with
ALTER TABLE ... DROP COLUMNonce everything downstream is updated
ALTER TABLE main.silver.orders DROP COLUMN dropped_col;
When Delta column mapping is enabled, this operation is metadata-only — fast and non-disruptive, no full table recreation needed.
The SELECT * Question
I get asked this constantly. The short answer: use it in Bronze, avoid it in Silver and Gold.
In curated layers, explicit column lists are the better practice. They make the data contract visible, reviewable, and testable. When you use SELECT * in Silver or Gold, new Bronze columns can flow downstream unexpectedly — which sounds convenient until it quietly breaks a BI semantic layer or an ML feature pipeline.
Explicit projections in PySpark work well here:
expected_cols = ["order_id", "customer_id", "order_ts", "status"]
silver_df = spark.table("main.bronze.orders").select(*expected_cols)
If Bronze evolves, Silver doesn’t unless you decide it should.
The Governance Model That Actually Works
Here’s a practical framework that balances flexibility and control:
And the operating model that makes this real:
Upstream teams announce additive and breaking changes before deployment — this is a lightweight data contract, not just a courtesy message
Data engineering validates in a lower environment before production rollout
Bronze accepts new columns safely when appropriate
Silver and Gold evolve only after a conscious design decision
Monitoring and tests detect unexpected schema drift early
Two Misconceptions Worth Clearing Up
Misconception 1: “Delta schema evolution means no engineering work after source changes.”
It means fewer ingestion failures. It does not mean curated transformations and downstream contracts maintain themselves. Those still require human decisions.
Misconception 2: “You have to drop and recreate tables after schema changes.”
Almost never. Delta tables can evolve in place, preserving history and avoiding disruptive rebuilds. Even when a column disappears from the source, table recreation is usually unnecessary — what matters is removing invalid downstream references and deciding later whether to drop the column from metadata.
The Final Position
Delta Lake schema evolution is best understood as a controlled flexibility mechanism.
It’s excellent for keeping Bronze ingestion robust when source systems add columns. It simplifies the physical handling of approved schema changes in Silver and Gold. But stable medallion pipelines still depend on clear ownership, explicit downstream contracts, and coordination between source teams and data engineers.
The tools work. The question is always whether the process around them is designed with enough intentionality.
Get that right, and schema changes stop being emergencies. They become routine — handled calmly, layer by layer, with history intact and consumers informed.
If you’re building on Databricks and want to go deeper on medallion architecture design, Unity Catalog governance, or PySpark transformation patterns — this is exactly the kind of topic we teach in RADE (Real-world AWS Data Engineering). Check out https://dataengineeringhub.in and https://sachinchandrashekhar.com for more.
Was this useful? Share it with a data engineer who’s dealt with a schema surprise at 2am. They’ll appreciate it.